网站日志可以从服务器下载,文件扩展名为日志下载后可以使用爱站工具包进行日志分析,可以分析蜘蛛抓取的网站目录网站页面蜘蛛ip但是免费用户只能查看20M以下的日志文件全文搜索引擎一般采用什么原理来采集信搜索引擎。
")
2蜘蛛分析包括概要分析,即所有不同的蜘蛛的访问次数停留时间总抓取量的数据分析目录抓取,即站点目录被抓取的数据量分析页面抓取,单个页面被抓取的数据量分析IP排行,不同IP地址的访问次数抓取量停留时长。
谷歌的叫Googlebot微软的叫bingbot搜狐的叫Sogou web spider腾讯的叫Sosospider因为国内主要是以百度为优化对象,我们来看看 百度蜘蛛爬行记录 分析,在日志记录中随便找一个百度蜘蛛 6。
只有我们的空间有了这样一个功能后,蜘蛛来到我们的网站了与服务器的对话才会被记录到IIs日志里面,我们通过分析IIS日志就可以知道蜘蛛来我们网站做了什么,爬取和收录了我们的哪些页面,包括蜘蛛来我们网站的爬取次数和地址。
六大功能一蜘蛛抓取 搜索引擎蜘蛛可以自由添加,除统计每个蜘蛛访问了多少次外,还统计每个蜘蛛访问了那些页,访问时间如果对同一个网页访问了多次,还可以知道首次访问时间和最后离开时间二页面受访 统计每个网页被。
通过分析网站日志Log文件可以看到用户和搜索引擎访问网站的数据,这些数据可以分析出用户和搜索引擎对网站的喜好以及网站的情况网站日志分析主要是分析蜘蛛爬虫的爬行轨迹蜘蛛爬虫抓取和收录的过程中,搜索引擎会给特定权重网站。
3搜索引擎也属于网站中的一类用户,我们今天的分享课,主要是针对搜索引擎这种用户在服务器留下的记录展开分析为了方便读懂搜索引擎日志,我们需要了解不同搜索引擎蜘蛛的标识,以下为4种搜索引擎的标识*百度蜘蛛Bai。
那么我们如何判断百度蜘蛛来过呢答案是要根据网站log日志,如果百度蜘蛛来过那么网站log日志中会有相关记录一个是百度蜘蛛名字 Baiduspider,一个是百度蜘蛛ip,这两点要综合考虑才能正确分析,下面我们说说具体如何操作1。
网站日志中出现大量的谷歌蜘蛛和百度蜘蛛,说明搜索引擎蜘蛛时常来光顾你的网站说到分析日志文件,我们就不得不说分析日志文件的时机了,那么在什么情况下我们要去分析日志文件呢?首先,新网站刚建立的时候,这个时候也是站长。
206以前没关注过,官方的解释是“服务器已经接受请求GET请求资源的部分请求必须 一个Range头信息以指示获取范围可能必须 IfRange头信息以成立请求条件”,304好像是指请求资源成功,但该资源较以前没有更新。
")
那就是中毒了,卸载了吧。
直接找到301状态码文件,修改301程序即可而且301并不会给网网站带来不好切记301的跳转网址,是否承接合理,是否对于跳转。
200是成功抓取302,文件移动。
百度用于抓取网页的程序叫做Baiduspider 百度蜘蛛,我们查看网站被百度抓取的情况主要是分析,网站日志里百度蜘蛛Baiduspider的活跃性抓取频率,返回的。
通过日志分析蜘蛛返回的状态码能及时发现网站里面是否存在错误或者蜘蛛无法爬取的页面,排查网站页面中存在的404错误页面,500服务器错误等这些噪音内容上噪音页面上重复页面,低质量页面,空内容页面,404页面,不排名页面等。
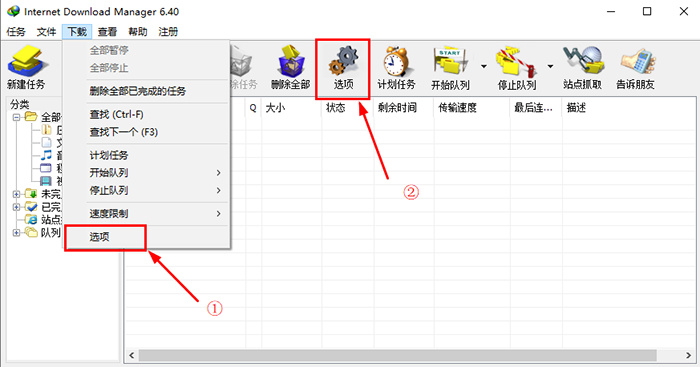
取消“全选”,找到百度蜘蛛的访客名称,选中并“确定”我们就可以得到日志当天百度蜘蛛访问网站的所有数据最后,该数据保存到网站每日分析日志中注意每日更新原创内容的网站一般在分析日志的时候还需要保留时间数据。
转载请注明:商兜网 » seo优化 » 蜘蛛日志分析(蜘蛛的日记有两个版本)
版权声明
本文仅代表作者观点,不代表B5编程立场。
本文系作者授权发表,未经许可,不得转载。